

In this first of a series of posts, I will be describing how to build a machine learning-based fake news detector from scratch. That means I will literally construct a system that learns how to discern reality from lies (reasonably well), using nothing but raw data. And our project will take us all the way from initial setup to deployed solution. Full source code here.
I’m doing this because when you look at the state of tutorials today, machine learning projects for beginners mean copy-pasting some sample code off the Tensorflow website and running it through an overused benchmark dataset.
In these posts, I will describe a viable sequence for carrying a machine learning product through a realistic lifecycle, trying to be as true as possible to the details.
I will go into the nitty-gritty of the technology decisions, down to how I would organize the code repository structure for fast engineering iteration. As I progress through the posts, I will incrementally add code to the repository until at the end I have a fully functional and deployable system.
These posts will cover all of the following:
- Ideation, organizing your codebase, and setting up tooling (this post!)
- Dataset acquisition and exploratory data analysis
- Building and testing the pipeline with a v1 model
- Performing error analysis and iterating toward a v2 model
- Deploying the model and connecting a continuous integration solution
With that let’s get started!
Building Machine Learning Systems is Hard
There’s no easy way to say this: building a fully-fledged ML system is complex. Starting from the very beginning, the process for a functional and useful system contains at least all of the following steps:
- Ideation and defining of your problem statement
- Acquiring (or labelling) of a dataset
- Exploration of your data to understand its characteristics
- Building a training pipeline for an initial version of your model
- Testing and performing error analysis on your model’s failure modes
- Iterating from this error analysis to build improved models
- Repeating steps 4-6 until you get the model performance you need
- Building the infrastructure to deploy your model with the runtime characteristics your users want
- Monitoring your model consistently and use that to repeat any of steps 2-8
Sounds like a lot? It is.
And here’s what the current machine learning tooling/infrastructure landscape looks like (PC to FSDL):
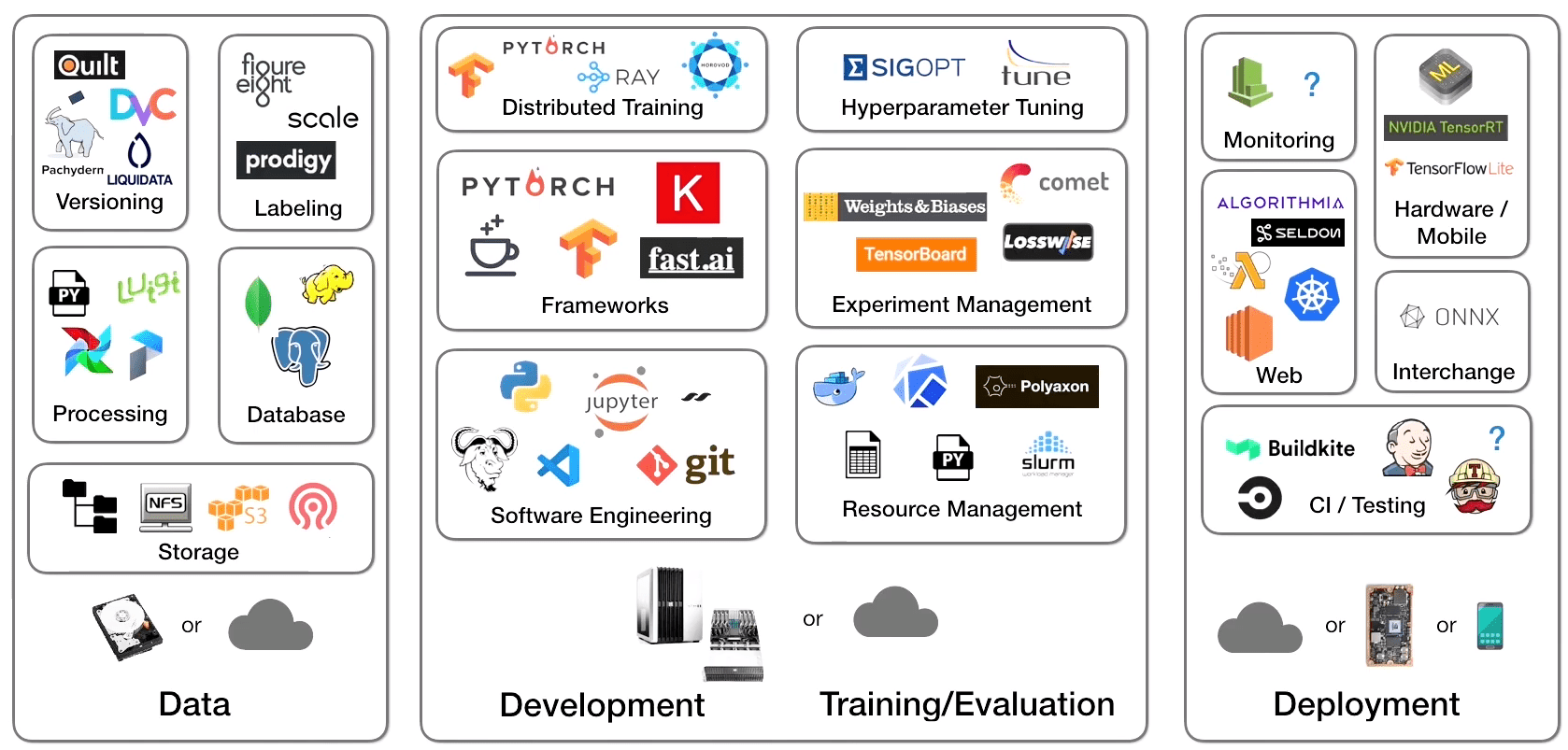
When you couple the inherent complexity of building a machine learning product with the myriad tooling decision points, it’s no surprise that many companies report 87% of their data science projects never making it into production!