

What’s bigger than a 175-billion-parameter natural language processing program?
A 178-billion-parameter program, of course. Such is just one of the attributes of Jurassic, a computer program introduced Wednesday by Tel Aviv-based artificial intelligence startup AI21 Labs.
GPT-3, of course, is the language program from the San Francisco-based startup OpenAI that rocked the world in 2020 by generating sentences and whole articles that seemed quite human-like. GPT-3 also shocked the world by being kept inside a fairly restrictive beta testing arrangement by OpenAI.
AI21 is promising to go OpenAI not one better, but two better, with what it claims are superior benchmark results on a test known as « few shot learning, » and a more open program for beta testers.
On the latter score, AI21 is making development use of the program available as an « open beta, » it said, where anyone can sign up to use the program and there is « no wait list. »
However, the amount of text generation is limited in the beta model. To deploy production-quality code that can serve predictions on demand, parties must submit an application for commercial-grade service and be approved by AI21.
One then uses AI21’s development program, AI21 Studio, to develop and deploy customized language models.
The startup, whose name stands for « AI for the 21st Century, » has some heavy hitters among its executive staff an advisors.
The founders are Stanford University professor Yoav Shoham, who serves as co-CEO; serial entrepreneur Ori Goshen, the other CEO; and Amnon Shashua, who is the CEO of Intel’s Mobileye unit that makes chips for self-driving cars, and who is also a computer science professor at the Hebrew University in Jerusalem and has many machine learning research projects to his name.
Advisors include Sebastian Thrun, a pioneer in autonomous vehicles, and Chris Ré, a Stanford University professor and a co-founder of AI computer maker SambaNova Systems.
AI21 has received $35.4 million in two rounds of venture funding.
In addition to the press release, AI21 posted a white paper describing Jurassic’s architecture and benchmark results against GPT-3. That paper is written by co-CEO Shoham, along with AI21 staffers Opher Lieber, Or Sharir, and Barak Lenz.
The paper details the architecture of Jurassic, its layout of different functional elements. In most respects, Jurassic is copying what OpenAI did in GPT-3, with one key departure.
The departure was made possible by a theoretical insight brought by Shashua and colleagues at Hebrew University that was presented at last year’s Neurips AI conference.
That research, led by Yoav Levine, along with Shashua, Noam Wies, Or Sharir, and Hofit Bata, argues there is an important trade-off in neural networks between what’s called width and depth.
Neural network depth is the number of layers of artificial neurons through which a given piece of input data is processed in sequence. The centerpiece of « deep learning » forms of AI is many more layers, hence greater depth. OpenAI’s GPT-3, in its « canonical » form, with 175 billion parameters, has a depth of 96 layers.
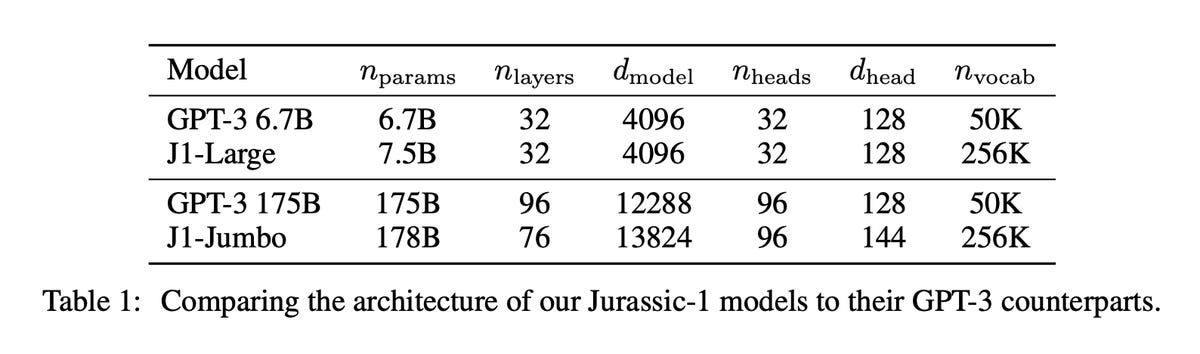
Width, by contrast, is the dimension of the vector that stores a representation of an input. For GPT-3, that is typically a vector of dimensions of 12,288.
In Levine and team’s research, they found that too many layers can lead to diminishing results for a deep learning program of the type « self-attention, » which is what GPT-3 is, and all programs like that are all built on the original Transformer program from Google.
As they phrase it, « for a given network size, » meaning, the number of parameters, « a certain network can be too shallow, as we predicted theoretically and corroborated empirically above, but it can also be too deep. » Hence, Levine and team conclude their is an optimal depth-width balance in the construction of a natural language program.
It is this insight that AI21’s Shoham and colleagues detail in their paper. « For a given parameter budget there is an optimal depth. » Specifically, they replace GPT-3’s 96 layers with just 76 layers, and they replace the vector width of GPT-3 of 12,288 with a width of 13,824.
Also: AI in sixty seconds
According to the Levine research, this should ultimately give Jurassic what’s called greater « expressivity, » which should be the quality of its language output. However, what the AI21 researchers observe is « a significant gain in runtime performance » when running their program on a GPU versus GPT-3:
By shifting compute resources from depth to width, more operations can be performed in parallel (width) rather than sequentially (depth). This is especially relevant to text generation where tokens are processed one at a time, and so there is less opportunity for parallelization, resulting in sub-optimal GPU utilization. In our benchmarks, comparing our architecture against GPT-3 175B on the same hardware configuration, our architecture has modest benefits in training time (1.5% speedup per iteration), but significant runtime gains in batch inference (7%) and text generation (26%).
One more thing that Shoham and team did with Jurassic was to boost the vocabulary size, the number of unique tokens that the program can ingest and keep track of, from the 50,000 that GPT-3 uses to 256,000. They also went beyond using tokens as just words to using « vocabulary items, » as they call them, where the units « contain a rich mixture of word pieces, whole words, and multi-word expressions. »
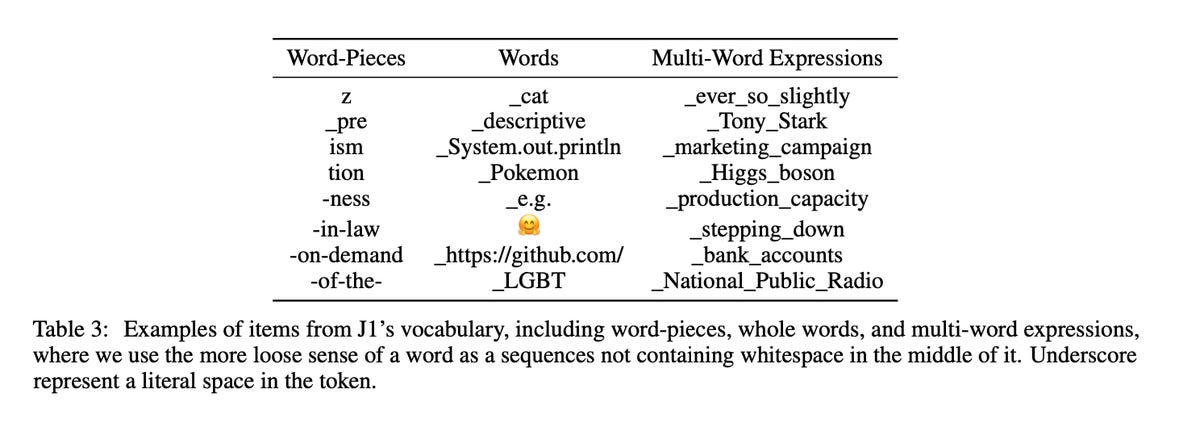
Again citing the work of Levine and team, the AI21 researchers argue that such flexible use of tokens is « more closely aligned with the semantic units of the text, including both named entities and common phrases, » and thus offers « several advantages, such as more sample-efficient training. »
The several advantages include what appears to be a big boost in test-taking relative to GPT-3. They provide data claiming Jurassic’s 178 billion parameters are comparable in accuracy to GPT-3 in what are called « zero-shot » tasks, where no example of human writing is provided at test time to the program.
Shoham and team’s main focus, however, is where GPT-3 particularly excels, which is tests known as « few-shot learning, » where several examples are first typed by a person, and the language program produces output by basically continuing the pattern of those examples.
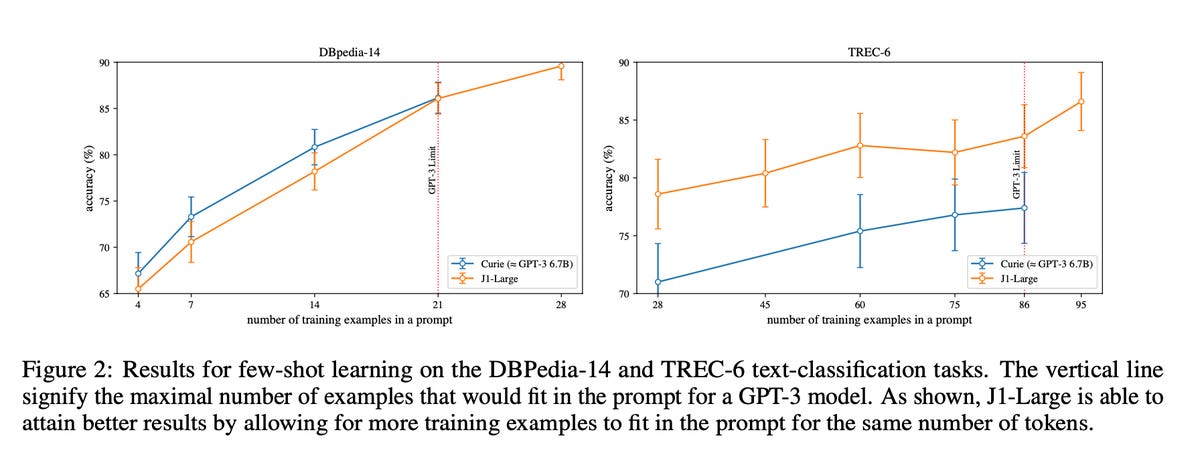
Think of the old game of analogies, « Microsoft is to desktop computers as Apple is to phones, and Burger King is to burgers as Kentucky Fried Chicken is to ______ », and the language program has to figure out what kind of answer is being asked for in the blank based on the pattern of relationships. That’s few shot, and it can be done for lots of kinds of tasks, including yes-no question answering and multiple-choice question answering.
Here, the authors claim the benefits of that more-flexible use of tokens. « One of its benefits is that in few-shot learning settings more training examples can fit in the prompt. » As a result, with the same overall number of training examples as given GPT-3, they claim greater accuracy, specifically because more examples can fit in the prompt.
Despite claiming what they believe are superior results, Shoham and team note up-front that « evaluation of few-shot learning is notoriously tricky, being subject to the vagaries of prompt choice. »
Hence, Shoham and team developed a test suite to address such challenges in the way that very large models are benchmarked against one another. They’ve posted that code on GitHub.
While the test results will probably be scrutinized many different ways as people kick the tires, the larger objective of AI21 seems to be to have built a more-accessible GPT-3 on the other side of the OpenAI wall, to take advantage, as a business, of the desire for many users to gain access to the capability.